ConcurrentHashMap
有参考 聊聊ConcurrentHashMap (opens in a new tab) ConcurrentHashMap 是如何成为一个线程安全的 HashMap (opens in a new tab)
ConcurrentHashMap 是 HashMap 的线程安全型的实现. 但 ConcurrentHashMap 在 JDK1.7 和 JDK1.8 的实现方式是不同的。
实现原理
JDK 1.7
ConcurrentHashMap 是由 Segment 数组结构和 HashEntry 数组结构组成. 把 KV 数据根据 hash 规则把哈希桶数组切分成若干个小数组 Segment , 每个 Segment 都包含若干个 HashEntry.
当一个线程访问其中一个 Segment 中的数据时,会把该 Segment 锁住, 其他 Segment 的数据也能被其他线程访问,实现了真正的并发访问.

Segment
Segment 继承了 ReentrantLock,所以 Segment 是一种可重入锁,扮演锁的角色。Segment 默认为 16,也就是并发度为 16。

HashEntry

JDK 1.8
ConcurrentHashMap 选择了与 HashMap 相同的Node数组+链表+红黑树结构.
在锁的实现上, 抛弃了原有的 Segment 分段锁,采用CAS + synchronized实现更加细粒度的锁.
将锁的级别控制在了更细粒度的哈希桶数组元素级别,也就是说只需要锁住这个链表头节点(红黑树的根节点),就不会影响其他的哈希桶数组元素的读写,大大提高了并发度。

为什么使用内置锁 synchronized替换 可重入锁 ReentrantLock ?
在 JDK1.6 中,对 synchronized 锁的实现引入了大量的优化,并且 synchronized 有多种锁状态,会从无锁 -> 偏向锁 -> 轻量级锁 -> 重量级锁一步步转换。
减少内存开销 。假设使用可重入锁来获得同步支持,那么每个节点都需要通过继承 AQS 来获得同步支持。但并不是每个节点都需要获得同步支持的,只有链表的头节点(红黑树的根节点)需要同步,这无疑带来了巨大内存浪费
添加元素
JDK 1.7
- 先定位到相应的 Segment ,
- 获取锁. 如果获取锁失败时
- 尝试自旋获取锁。
- 如果重试的次数达到了 MAX_SCAN_RETRIES 则改为阻塞锁获取,保证能获取成功。
- 获取到锁执行 put 操作
JDK 1.8
- 计算 hash 定位到指定 Node
- 如果 Node 为 NULL, 说明当前hash下无数据, 通过 CAS 锁住当前 Node. 直接添加即可
- 如果再扩容, 参与扩容.
- 如果节点已经存在了, 那么就通过 synchronized 锁住 Node. 插入元素
- 当在链表长度达到 8 的时候,数组扩容或者将链表转换为红黑树。
获取元素
JDK 1.7
根据 key 计算出 hash 值定位到具体的 Segment ,再根据 hash 值获取定位 HashEntry 对象,并对 HashEntry 对象进行链表遍历,找到对应元素。
JDK 1.8
根据 key 计算出 hash 值,判断数组是否为空;
如果是首节点,就直接返回;
如果是红黑树结构,就从红黑树里面查询;
如果是链表结构,循环遍历判断。
由于相关数据字段均是使用 volatile 修饰, 每次获取时都是最新值, 因此无需加锁.
key 为啥不能为 NULL
因为 ConcurrentHashMap 是用于多线程的 ,如果ConcurrentHashMap.get(key)得到了 null , 这就无法判断,是映射的value是 null ,还是没有找到对应的key而为 null ,就有了二义性。
JDK1.7 与 JDK1.8 中ConcurrentHashMap 的区别?★★★★★
- 数据结构:取消了 Segment 分段锁的数据结构,取而代之的是数组+链表+红黑树的结构。
- 保证线程安全机制:JDK1.7 采用 Segment 的分段锁机制实现线程安全,其中 Segment 继承自 ReentrantLock 。JDK1.8 采用CAS+synchronized保证线程安全。
- 锁的粒度:JDK1.7 是对需要进行数据操作的 Segment 加锁,JDK1.8 调整为对每个数组元素加锁(Node)。
- 链表转化为红黑树:定位节点的 hash 算法简化会带来弊端,hash 冲突加剧,因此在链表节点数量大于 8(且数据总量大于等于 64)时,会将链表转化为红黑树进行存储。
- 查询时间复杂度:从 JDK1.7的遍历链表O(n), JDK1.8 变成遍历红黑树O(logN)。
JDK 8 源码解读
计算 Hash
与 HashMap 基本一致, 但增加了一步骤, 与最大的 int 整数 Integer.MAX_VALUE 进行与操作, 这样可以避免 hash 为负数,
因为在ConcurrentHashMap中,Hash值为负数有特别的意义,如-1表示ForwardingNode结点,-2表示TreeBin结点。
put 值
- 计算 hash. 以便获取 index
- 如果尚未初始化 table. 先初始化 table
- CAS 循环取 table[index].
- 如果为空, CAS循环初始化新的Node放到链表的首位
- 如果不为空, 判断是否在 forwarding nodes 状态.
- 如果是的话, 参与判断当前节点是否在 forwarding nodes 状态. 是的话参与进去
- 如果不是, 锁住 table[index] . 执行 put 操作. 插入值
- 判断是否需要转化为红黑树
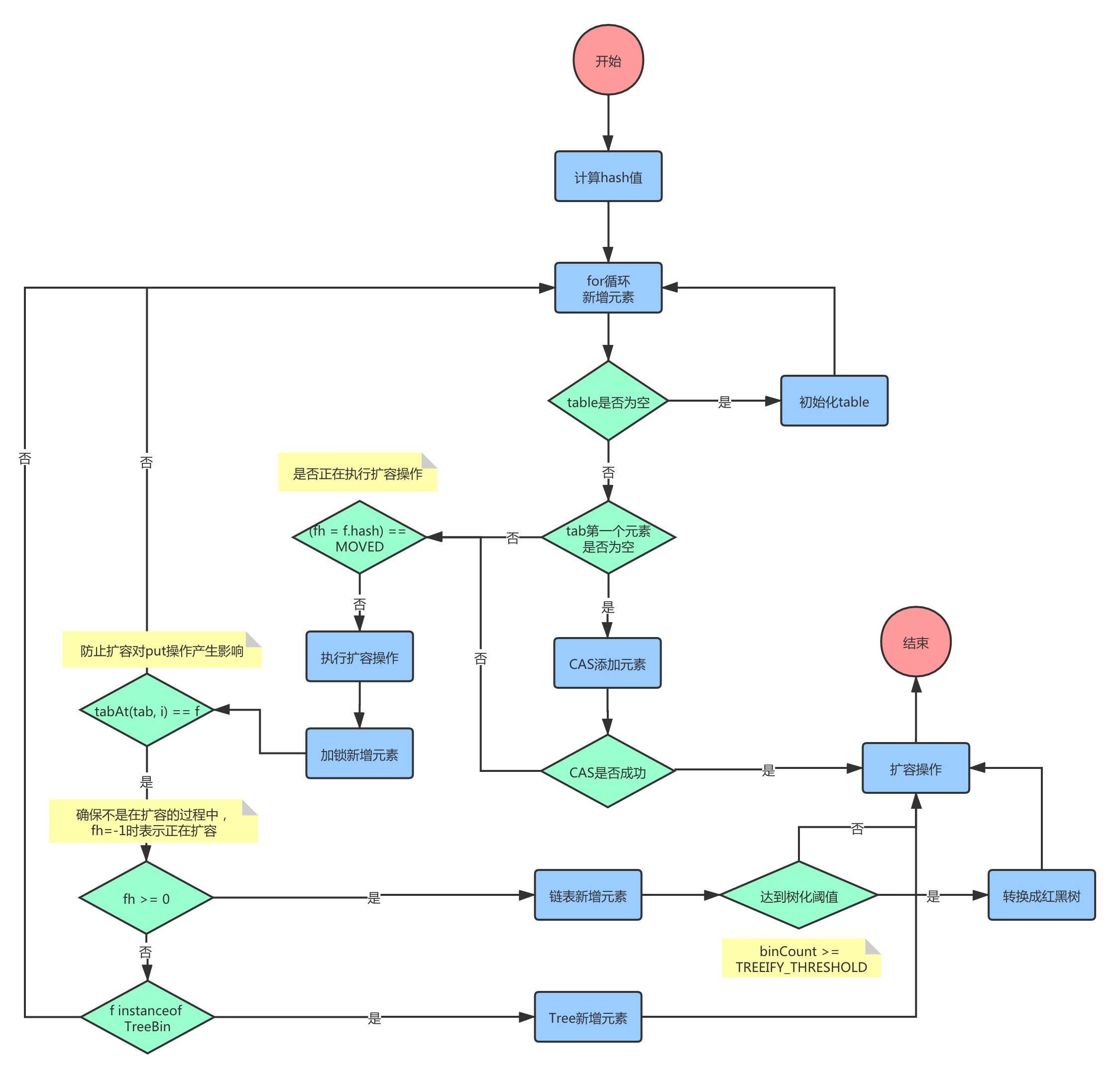
扩容
参考 https://blog.csdn.net/zzu_seu/article/details/106698150 (opens in a new tab)
在 addCount 重新计算 size 中.
- 重新计算 count(). count() 如果大于下一个扩容标识, 进行扩容. 如果扩容,
- 重新计算 resizeStamp. resizeStamp(n) 的返回值为:高16位置0,第16位为1,低15位存放当前容量n,用于表示是对n的扩容。
- 如果 sc < 0 则已经在扩容了, 把当前线程加入进去. 参与扩容
- 如果 sc > 0 启动扩容 transfer.
transfer 扩容:
- 新建扩容一倍的数组
- 每个线程在扩容时拿到的长度,最小为16。
什么时候会扩容?
桶上链表长度达到 8 个或者以上,并且数组长度为 64 以下时只会触发扩容而不会将链表转为红黑树 。
sizeCtl默认的情况下等于0,对ConcurrentHashMap进行初始化的时候会对sizeCtl减1,初始化成功后将sizeCtl改为阈值(最大长度*0.75)。