HashMap
为什么 HashMap 的加载因子是0.75?
在理想情况下,使用随机哈希码,在扩容阈值(加载因子)为0.75的情况下,节点出现在频率在Hash桶(表)中遵循参数平均为0.5的泊松分布。忽略方差,即X = λt,P(λt = k),其中λt = 0.5的情况,按公式:
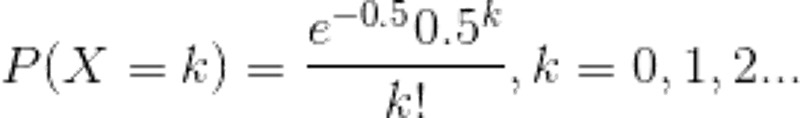
计算结果如上述的列表所示,当一个bin中的链表长度达到8个元素的时候,概率为0.00000006,几乎是一个不可能事件。
那么为什么不可以是0.8或者0.6呢?
对于开放定址法,加载因子是特别重要因素,应严格限制在0.7-0.8以下。超过0.8,查表时的CPU缓存不命中(cache missing)按照指数曲线上升。 因此,一些采用开放定址法的hash库,如Java的系统库限制了加载因子为0.75,超过此值将resize散列表。 选择0.75作为默认的加载因子,完全是时间和空间成本上寻求的一种折衷选择。
HashMap 和 HashTable 有什么区别?
①、HashMap 是线程不安全的,HashTable 是线程安全的;
②、由于线程安全,所以 HashTable 的效率比不上 HashMap;
③、HashMap最多只允许一条记录的键为null,允许多条记录的值为null,而 HashTable不允许;
④、HashMap 默认初始化数组的大小为16,HashTable 为 11,前者扩容时,扩大两倍,后者扩大两倍+1;
⑤、HashMap 需要重新计算 hash 值,而 HashTable 直接使用对象的 hashCode
初始化
threshold: 初始化时将阈值置为大于初始容量(initialCapacity)容量的2的幂值 (比如 initialCapacity 为 15, 那么 threshold 即 16, 比如 initialCapacity 为 800, 那么 threshold 即 1024)
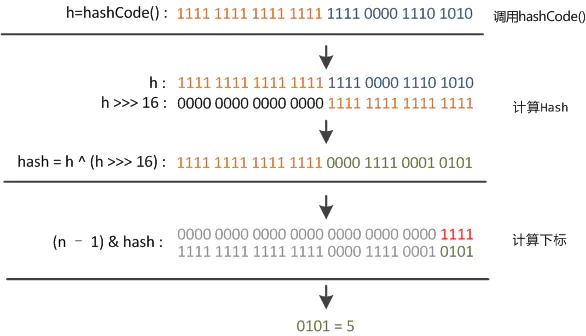
对 key 进行 hash 运算
key 为 null 时 hash 即为 0, key 不为 null 时计算对象 key 自身的hashcode运算得到的 32 int 整数的高低16为为进行异或运算
这么做的目的是为了混合哈希值的高位和地位,增加低位的随机性。并且混合后的值也变相保持了高位的特征。
见下图
插值
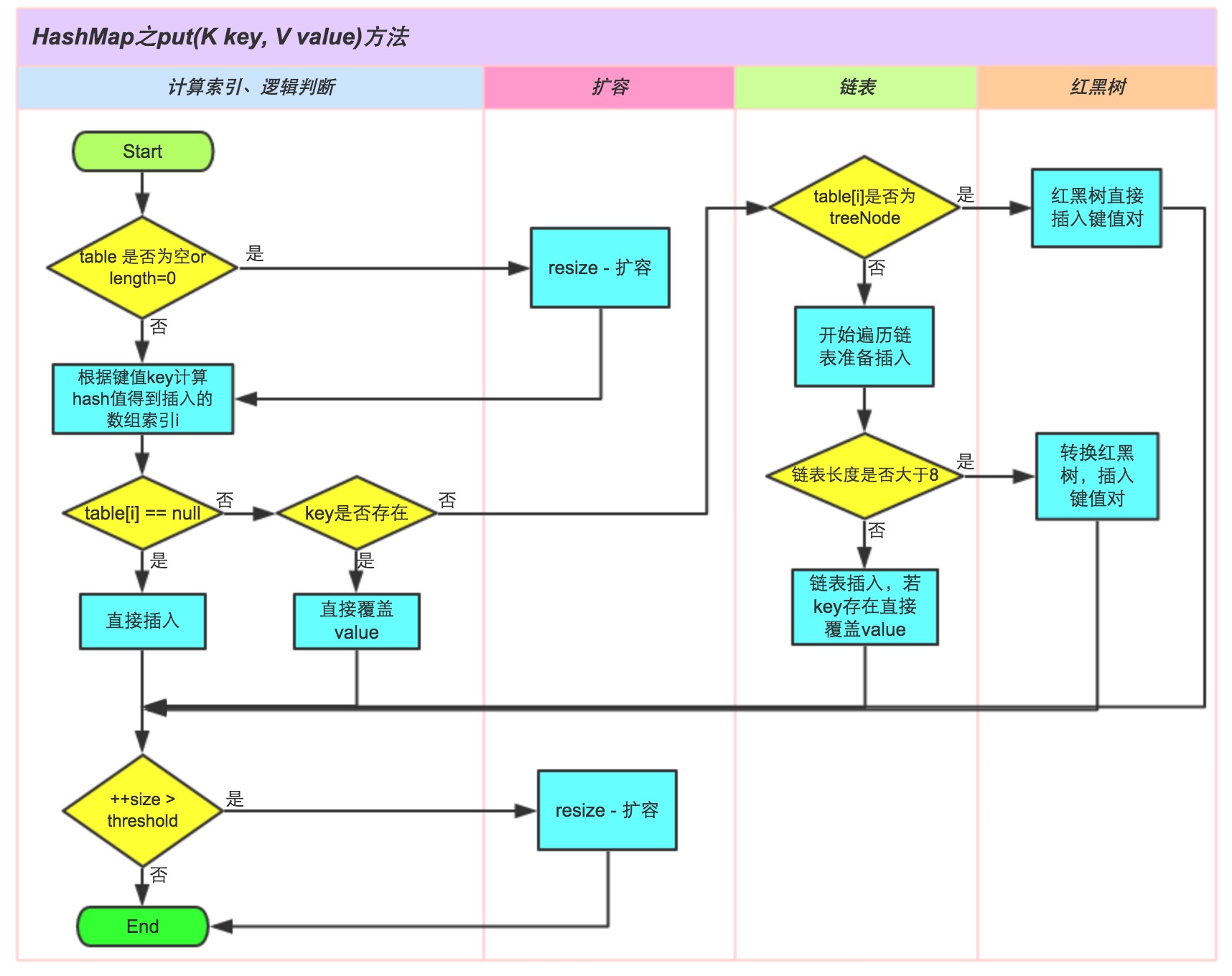
- 如果 table 没有初始化 -> 初始化
- 对 key 执行 hash 运算后与当前容量进行与操作(避免超出索引), 得到当前 key 在数组中的索引位置 index
- 判断 table[index] 如果 table[index] 为空, 直接 new Node 存放到位置中.
2. 如果 table[index] 不为空.
- 判断 key 是否相等, 相等直接覆盖
- key 不相等时, 如果是 TreeNode (红黑树). 往书里面插值
- 如果是链表, 如果新增后的值到红黑树的阈值, 那么直接转化为红黑树, 否则链表插入值
- 如果长度超出阈值, 需要扩容
扩容
- 如果当前容量大于最大支持的容量 1 < < 30. 那么不再扩容, 直接把阈值设置为整数的最大值
- 其他时候扩容. double 扩容. 容量和阈值均左移一位, 设置为原来的两倍, 新建一个新容量数组来存放
- 扩容完毕, 重新拷贝数组. 对原始key的hash值与容量进行与运算重新计算 index, 由于新容量与旧容量是 double 扩容的, 因此只有新容量的最高位与旧的是不一致的, 原来是 0 ,新的是1. 在做与运算时, 与原来的值相比, 只有两种结果, 0 或 1
-
如果是0, 那么新的index与原来的保持不变
-
如果是1. 那么将旧数据赋值到新的index上.
-
这么做可以保证扩容前的旧数据是可以近似均匀的分布到扩容后的数据中的.
-
其中需要注意的是, 如果原来是链表, 那么拷贝完依然是链表, 如果是红黑树, 那么分散之后, 需要重新计算, 不满足树的, 维持链表, 如果满足树, 重新计算为树.
-
HashMap初始容量为什么是2的n次幂及扩容为什么是2倍的形式?
两个原因: 1.得到的新的数组索引和老数组索引只有最高位区别,更快地得到新索引
- HashMap的初始容量是2的n次幂,扩容也是2倍的形式进行扩容,是因为容量是2的n次幂,可以使得添加的元素均匀分布在HashMap中的数组上, 减少hash碰撞,使得查询效率降低!